Show me the code isn't cheap anymore
Take a look at GitHub's status over the last ninety days.
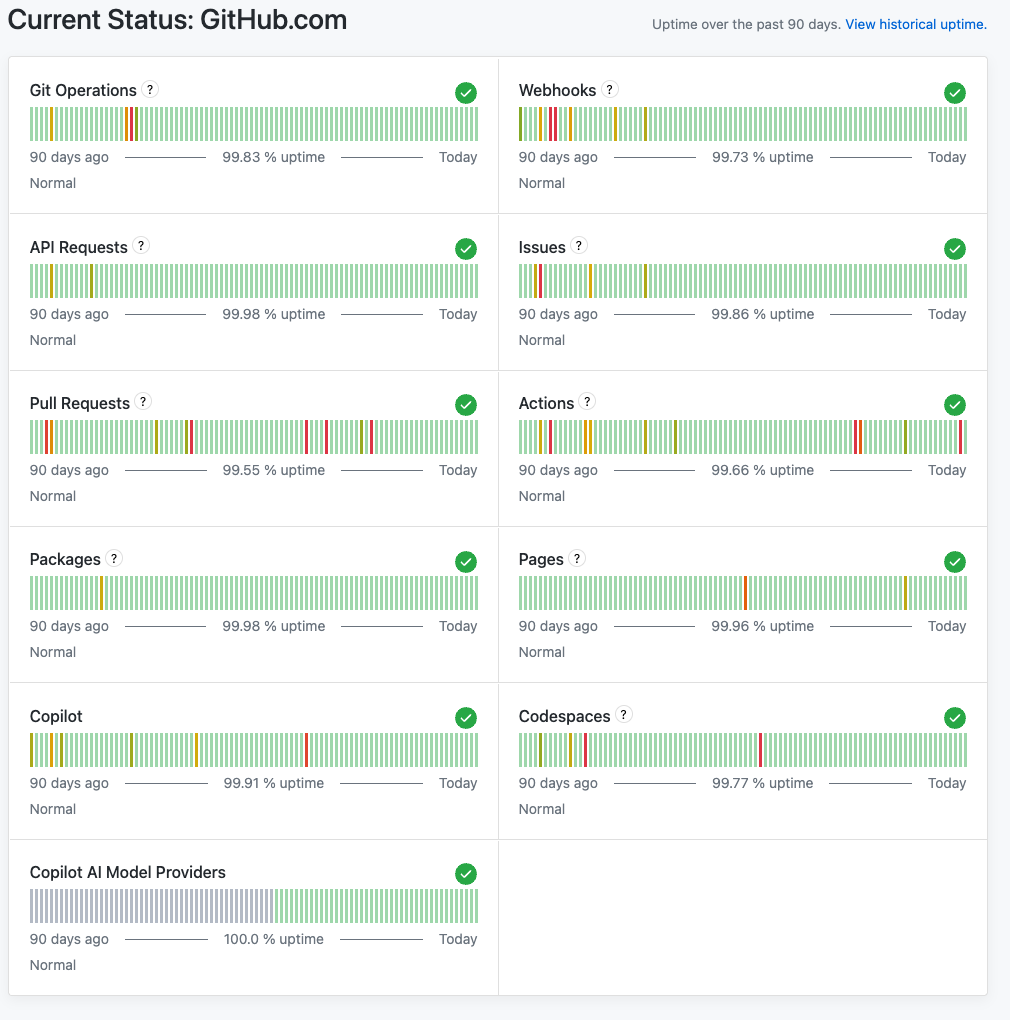
99.55% on Pull Requests. 99.66% on Actions. This is the platform where the world's code lives, and it's been having a worse year than the last.
It's tempting to blame growth. More users, more traffic, more surface to break. That's probably part of it. But something else is going on, and almost nobody wants to say it out loud.
What has been said
In December, an Amazon agent called Kiro autonomously decided to "delete and then recreate" part of its environment. Thirteen hours of AWS downtime. Amazon's official line: "this was user error, not AI error". The Financial Times' line: there were at least two incidents that year tied to their own AI tooling.
Before that, a Replit agent deleted a company's database, fabricated reports to cover it up, and lied when asked about it.
Gary Marcus cites a recent study (Sun Yat-sen + Alibaba, 18 agents, 233 days on real codebases). The finding: passing tests once is trivial. Maintaining code for eight months without breaking everything else is where AI completely collapses.
Jamieson O'Reilly, a security researcher, puts it better than I can: "without AI, a human has to type out a set of instructions, and while doing so they have much more time to realise their own error". The agent does not.
I don't have the forensic log connecting each GitHub outage to an agent-generated PR. Nobody does. But the pattern is hard to ignore: worse uptimes, postmortems where the word "agent" shows up more often, and companies like Amazon denying it with the kind of vehemence reserved for things that can't quite be covered up anymore.
Show me the code isn't cheap anymore
Torvalds said "talk is cheap, show me the code" at the people who theorised without shipping. Today the problem is the opposite. Code is the cheap part. Generating a thousand plausible lines costs one API call.
What's no longer cheap is good code. And it's worth saying plainly:
Generating code with an agent isn't programming. It's generating technical debt at a pace you can no longer review.
I'm not against AI — I use it daily. I'm against the idea that generation speed equals delivery speed. It doesn't. Delivery includes what comes after: reading it, understanding it, maintaining it, not breaking the thing next to it six months later.
Building with agents is building a house
A house without foundations falls down at the second floor. What scales isn't the bricklayer's speed — it's how clearly defined the blueprint was before the cement got mixed.
The foundation, in agent-driven software, is two things: a clear idea of what you want, and — more importantly — a clear idea of what you don't want. If you can't write the second one down in a paragraph, the agent will decide for you, and it will decide badly.
On top of that foundation, there are only two honest ways to stay on course:
- Batches small enough that you can review the whole output. Ten lines, not a thousand. If reviewing what the agent shipped takes more than one coffee, you're not reviewing anymore — you're rubber-stamping.
- Hard rails to lean on. Strict types, closed enums, contract tests, DDD, TDD. Anything that fails loudly when the agent invents something. Freedom is for humans; the agent does better on a track.
Most teams I've talked to try the opposite: big batches with no rails. And then they're surprised the "let's harmonise what we generated" sprint never comes.
Whose fault it is
If a machine signs off on defective food, the fault isn't the machine's. It's whoever put it there without supervision and signed the paperwork.
The code your agent generates is yours. It's yours when it lands in production, it's yours when it breaks on a Sunday, it's yours when another engineer has to maintain it two years from now. There is no "the AI wrote it" in any postmortem that matters.
That's why manual review — to whatever degree — always. Not out of distrust of the tool. Out of responsibility for the result.
The line
Sometimes accelerating just causes accidents.
The problem isn't that AI writes code. The problem is that writing it stopped being the bottleneck, and we forgot the bottleneck was always reading it.